
Twenty years ago, it was easy for an operating system kernel to go idle: when there were no tasks to run, “the idle loop” would be scheduled. Early idle loops were basically empty infinite loops that did nothing while waiting for the next interrupt to happen. This saved power simply by avoiding running instructions that needed power hungry components such as the cache or FPU!
Over time, changing technology has allowed multiple additional hardware mechanisms to reduce power to be introduced. With these new options available, today the idle loop is responsible for choosing and deploying the “best” way to go idle.
As a brief reminder, entering and returning from an idle state has a cost and that cost can be measured both in time and in energy. Typically the shallowest idle state is “nearly free” to enter/exit whilst deeper idle states have increasingly higher costs to enter and exit. If the system enters a deep idle state and wakes up soon after sleeping then energy will have been wasted because the energy cost to enter the deep idle state is greater than the energy saved whilst residing in that state.
cpuidle is the kernel sub-system that governs idle state transitions. Like cpufreq, mechanism is separated from policy, through the use of drivers and governors.
- cpuidle drivers provide the mechanism needed to enter and exit idle states. They enumerate the available idle states to the governor. As part of that they describe to the governor the energy saving properties of each state. Finally drivers are able to enter idle states at the request of the governor.
Drivers can be fully customized for the unique properties of each System-on-Chip (SoC). However CPU idle states are often well supported by low-level platform firmware and made available to the kernel using standard interfaces such as PSCI (Power State Coordination Interface) on Arm and SBI (Supervisor Binary Interface) on RISC-V. Thus whilst there is scope for per-SoC drivers, in reality these are becoming unusual. Most modern architectures, including both Arm and RISC-V, define standardized interfaces allowing a single Arm and single RISC-V driver to be shared by a wide range of SoC families.
- cpuidle governors provide policy and are responsible for choosing the “best” idle state from among those available.
The governors use the information from the drivers, together with gathered data about historic or known-future events (such as timer wakeups) to make an “educated guess” about when the CPU will need to leave the idle state due to an interrupt. Based on the estimated wake up time it can select the idle state likely to save the greatest amount of energy.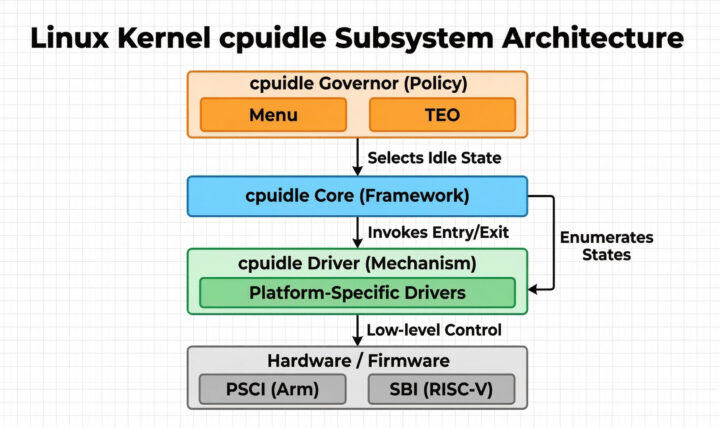
How do cpuidle governors make decisions?
cpuidle governors receive data about the physical characteristics of the system from the cpuidle driver. This takes the form of a list of idle states, where each state is annotated with a target residency. Target residency is the minimum time a CPU must spend in an idle state to save energy compared to shallower states. In other words, although the target residency is measured in time, it actually provides data that allows the governor to compare the energy cost of entering and exiting the different idle states. There are three possibilities when a system leaves an idle state:
- If a system is awakened before reaching the target residency time then the system wasted energy by selecting an idle state that was too deep
- If a system remains in an idle state for longer than the target residency time of a deeper idle state (if there is one) then the system wasted energy because the deeper idle state would have saved more energy
- If a system was woken after reaching the target residency time for our selected state but before reaching the target residency of a deeper idle state then the choice was optimal
All cpuidle governors keep track of historic idle entry/exit timings, in fact they make them visible for each CPU at /sys/devices/system/cpu/cpu<N>/cpuidle so you can check them yourself!
The governors assume that the length of recent idle periods can be used to predict the future. In fact the ladder governor (used in systems with a regular scheduler tick) and haltpoll governors (specialized governor for virtual machines) work exclusively using historic data.
Other governors, such as menu and teo (timer-event oriented), receive a glimpse into the future, although that view is rather limited. In general, drivers don’t report when they expect their interrupts will fire but there is one interrupt that can be predicted “perfectly”: we always know when the next timer interrupt is due. Thus the upper bound for any idle period is the time to the next timer interrupt. For many use-cases, timer interrupts are significantly more frequent than any other. That means that, providing historic entry/exit tracking suggests we are running shows that we are running a use-case dominated by the timer interrupt then it is an excellent predictor of idle time.
The final factor at play in governance decisions is the energy cost of the decision making itself! All computation has an energy cost. It doesn’t matter if the governor makes the best decision if it burns too much energy making the decision! This is especially true when the system is experiencing short idle periods. In that case making a fast decision to enter the shallowest idle state is extremely desirable!
The menu and teo governors both use the timer to inform decisions but adopt different strategies:
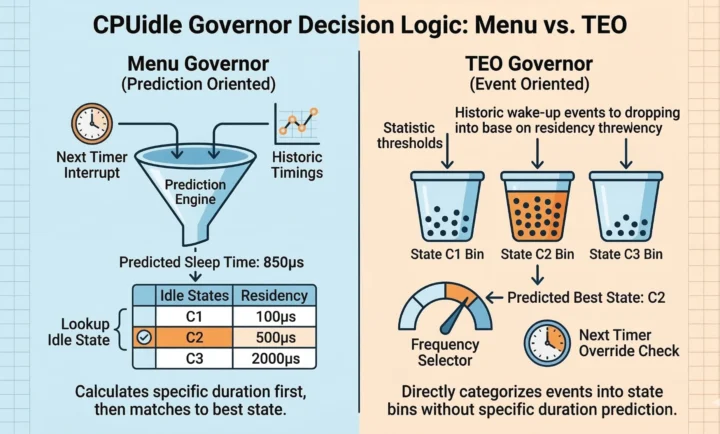
- The menu governor seeks to generate a predicted sleep time by taking the next wake up time and applying a correction factor derived from recent history to adjust it. Once it has made a prediction it can look up the best idle state.
- The teo governor quantizes the historic information into bins based on the target residency times for each idle state. The quantized data does not allow prediction the idle time but, because each bin corresponds to a specific idle state, it is still able to predict which idle state will be best! It then uses the next wake up time to improve the choice by selecting a shallower mode if the timer will fire shortly.
Additional detail about the menu and teo governors in the Linux kernel documentation.
Tuning Idle Behaviour for Lower Power Consumption
All cpuidle governors share something in common with the schedutil governor: the governors themselves do not offer any tuneable values to tweak their heuristics. As we saw before that doesn’t mean there is nothing for us to tune, just that to conserve power (or improve performance) we have to look outside of the governor itself. Today we’ll be discussing some of those options.
Going tickless
For many years Linux managed the flow of time by establishing a timer that fired 100 times per second and using this “scheduler tick” to swap processes and handle timer expiry in drivers. This tick is configurable and the scheduler tick can be set to 100, 250 or 1000Hz. Changing CONFIG_HZ can have profound effects on system behaviour and it is an interesting kernel tuneable when seeking to balance power consumption and interactivity (although which value results in the lowest power consumption varies with workload).
When CONFIG_HZ is set to the minimum value and the system is waking up 100 times a second, the system can never go idle for more than 10ms. Waking up this frequently can reduce the effectiveness of deep-idle states and should be avoided on systems that seek to conserve energy this way.
Tickless kernels either disable the scheduler tick when the system goes idle (CONFIG_NO_HZ_IDLE=y) or when there is only a single task running on the CPU (CONFIG_NO_HZ_FULL=y). Setting either option allows longer residency in idle states. The exact difference between these options is subtle and not in scope for this post. See NO_HZ: Reducing Scheduling-Clock Ticks if you are interested in more!

Finally we should note that there is little point in going tickless if there is a driver that wakes up 100 times a second to poll, for example, an SPI peripheral! If you have gone tickless you should also make sure that the code running on your system doesn’t introduce unnecessary periodic ticks by polling for status. Note also that if polling cannot be avoided then it’s still important to ensure the driver shuts the polling down when there are no clients.
Try a different cpuidle governor
If you have a tickless system there is a choice of two governors: menu and teo (timer-event oriented).
The menu governor is the default and works by predicting how long the system will be idle for. It monitors the historic wake up intervals and the due time of the next timer interrupt, filtering them to identify the “typical” wake up interval. It then uses that prediction to choose from the menu of choices offered by the cpuidle driver.
The teo governor uses the same sources of data but tracks the statistical data to directly predict the best idle state, without predicting exactly how long it expects the system to remain idle for. When the system wakes up frequently this allows it to avoid the (relatively expensive) peek at the timer queue reducing energy costs of its decision making.
The governor can be inspected and changed via sysfs: /sys/devices/system/cpu/cpuidle/current_governor.
Power Management Quality of Service (PM QoS) Requests
Author Daniel Thompson, RISCstar Solutions
As mentioned in the introductory sections, entering/leaving idle state has a cost that can be measured in both time and in energy. The cpuidle governor usually makes decisions based on energy cost but there are situations where we have to consider the time cost as well. For example if we are in a deep idle state it can take a long time to get the CPU running again. What if an important interrupt arrives during a deep idle state and we don’t respond fast enough? We don’t want the idle system to cause us to miss real-time deadlines, such as refilling an audio buffer.
One way to solve this is to disable the deep idle state, but doing that globally will cause energy to be burned unnecessarily when not running time-sensitive applications.
A better way to address this is ensure all drivers and userspace register their latency tolerance with the PM QoS framework. The latency tolerance is a value in microseconds that expresses how much additional latency due to CPU idling a driver or userspace process can tolerate before their performance is degraded. cpuidle chooses the lowest values among all drivers and processes and prevents the governor from adopting deep idle states if the entry/exit time is too long.
This is great for modal systems where entering deep idle states is useful for conserving power but it is not appropriate to enter deep idle states in all modes.
Wrapping up
In this blog we have covered how cpuidle works and also looked at the ways we can tune systems using modern features based on schedutil and the timer-event oriented CPU idle governor.
This has been limited to cpuidle and the hardware that it is built on. There are many other avenues we could explore. For example we haven’t looked at how runtime PM allows us to manage the energy used by peripheral devices. Even having focused on the CPU there’s still plenty we could say on topics like thermal management or SMP load balancing. Load balancing is especially interesting on heterogeneous CPU such as Arm’s pioneering big.LITTLE technology since it provides the chance to conserve power by migrating tasks to more efficient processors.
For now, let’s close by noting that power management tuning is a practical skill that requires embedded Linux developers to understand the requirements and limitations of the workload. We’ve focused on features here rather than hardware. In fact the Arm laptop used for examples wasn’t selected because it’s a great example of an embedded Linux system, it was selected because we knew it was free of any NDAs! Reviewing your own hardware is a great way to augment what you learned here. Combining knowledge about the kernel tools, your workload and your platform puts you in the best position to build systems with state-of-the-art battery life and performance.



